梦金指南网
梦金指南网如何在NVIDIA CUDA Tile中编写高性能矩阵乘法
本博文是系列课程的一部分,旨在帮助开发者学习 NVIDIA CUDA Tile 编程,掌握构建高性能 GPU 内核的方法,并以矩阵乘法作为核心示例。
在本文中,您将学习:
如何使用 NVIDIAcuTile实现高性能矩阵乘法:深入理解平铺加载、计算与存储的执行流程。
块级并行编程思维的转变:从线程级思考逐步过渡到以线程块为核心的编程模式。
平铺编程的优化实践:通过实际代码掌握性能调优的关键策略。
开始之前,请确认您的环境符合以下要求(更多详情请参阅快速入门):
环境要求:
CUDA 13.1或更高版本
GPU 架构:NVIDIA Blackwell(例如,NVIDIA RTX 50 系列)
Python:3.10 及以上版本
安装 cuTile Python:
| pip install cuda-tile |
注意:cuTile 是 NVIDIA 推出的新一代 GPU 编程框架。尽管目前仅支持针对 Blackwell(计算能力 10.x 和 12.x)架构的优化,但即将发布的 CUDA 工具包版本将扩展对更多架构的支持。
什么是矩阵乘法?
矩阵乘法是现代技术计算中的一项基本运算,它是求解方程组的基础,支撑着图形处理、模拟、优化以及多数机器学习任务,并能高效地映射到 GPU 等高性能硬件上。
给定输入矩阵 A (M×K) 和 B (K×N),计算结果矩阵 C (M×N) 中各元素的公式如下。

从公式可以看出,矩阵 C 的元素是通过计算矩阵 A 的行与矩阵 B 的列的点积得到的。
图块编程可以通过将输出矩阵划分为多个图块,既能简化实现,又能实现优异的性能。每个图块负责计算输出矩阵的一个子块,cuTile 会自动处理内存访问和线程同步。具体而言:
每个块处理输出矩阵 C 的 (tm×tn) 图块。
沿 K 维度循环,依次加载矩阵 A 和 B 对应的图块。
调用ct.mma()执行矩阵乘积累加运算(自动启用 Tensor Core)。
最终,将累积结果写回全局内存。
图 1 展示了计算过程,其方式类似于逐个元素的算法,但在本例中,图块取代了单个元素。
图 1。矩阵乘法 (A + B + C) 分解为图块的示意图
GPU 内核实现
在介绍完核心理念之后,我们来看一下完整的实现代码。代码分为两部分:一部分是在 GPU 上运行的内核,另一部分是在 CPU 上启动的代码,如下所示。
| import cuda.tile as ct from math import ceil import torch # Type alias for compile-time constants ConstInt = ct.Constant[int] # Step 1: Define the kernel @ct.kernel def matmul_kernel(A, B, C, tm: ConstInt, tn: ConstInt, tk: ConstInt): # 1.1 Get block ID and map to output tile position # inside swizzle_2d, we access ct.bid(0) and output bidx and bidy bidx, bidy = swizzle_2d(M, N, tm, tn, GROUP_SIZE_M) # 1.2 Calculate the number of tiles along the K dimension num_tiles_k = ct.num_tiles(A, axis=1, shape=(tm, tk)) # 1.3 Initialize accumulator accumulator = ct.full((tm, tn), 0, dtype=ct.float32) # 1.4 Loop over K dimension for k in range(num_tiles_k): # Load tiles from A and B a = ct.load(A, index=(bidx, k), shape=(tm, tk)) b = ct.load(B, index=(k, bidy), shape=(tk, tn)) # Matrix multiply-accumulate accumulator = ct.mma(a, b, accumulator) # 1.5 Store result ct.store(C, index=(bidx, bidy), tile=accumulator) # Step 2: Launch the kernel def cutile_matmul(A: torch.Tensor, B: torch.Tensor) -> torch.Tensor: # Choose tile sizes tm, tn, tk = 128, 256, 64 # for float16 # Calculate grid dimensions grid_x = ceil(m / tm) grid_y = ceil(n / tn) grid = (grid_x * grid_y, 1, 1) # Create output and launch C = torch.empty((m, n), device=A.device, dtype=A.dtype) ct.launch(stream, grid, matmul_kernel, (A, B, C, tm, tn, tk)) return C |
现在,我们来逐步分解每个关键部分。
1.定义 GPU 内核
在 cuTile 中,@ct.kernel装饰器用于将普通的 Python 函数标记为 GPU 内核:
| @ct.kernel def matmul_kernel(A, B, C, tm: ConstInt, tn: ConstInt, tk: ConstInt): # Kernel code here |
此装饰器表示:
此函数将在 GPU 上执行。
每个线程块将运行该函数的一个独立实例。
它无法被直接调用,必须通过ct.launch()来启动。
2. 编译时优化:常量类型的标注
请注意,参数tm、tn和tk采用特殊类型标注ct.Constant[int]:
| ConstInt = ct.Constant[int] # Define type alias def matmul_kernel(A, B, C, tm: ConstInt, # Tile size along M dimension tn: ConstInt, # Tile size along N dimension tk: ConstInt): # Tile size along K dimension |
这表明它们是编译时常量。cuTile 会针对不同的图块大小值生成专用的机器代码,从而使编译器能够:
执行循环展开。
优化内存访问模式。
生成高效 Tensor Core 指令。
3.确定工作范围:块 ID 映射
每个块负责计算输出矩阵的特定图块。通过swizzle_2d()函数,我们获取当前正在处理的块的索引:
| def swizzle_2d(M, N, tm, tn, GROUP_SIZE_M): # Get the global IDs of the current CUDA block (CTA) in a 1D grid. bid = ct.bid(0) return swizzle_2d_from_bid(M, N, tm, tn, GROUP_SIZE_M, bid) bidx, bidy = swizzle_2d(M, N, tm, tn, GROUP_SIZE_M) |
此代码的功能是确定当前块应处理的输出矩阵中的哪个图块。为了理解该过程,我们首先从主机端的网格划分开始。
第 1 步:主机侧网格划分
在主机端启动核函数时(如第 3 节所述),计算所需的任务块数量:
| grid_x = ceil(m / tm) # Number of Blocks needed for M dimension grid_y = ceil(n / tn) # Number of Blocks needed for N dimension grid_size = grid_x * grid_y # Total Blocks grid = (grid_size, 1, 1) # Defined as a 1D grid |
m和n: 输出矩阵 C 的行和列。
tm: 输出图块大小行方向 (M 维)由每个块处理。
tn: 按列方向( N 维)输出每个块处理的图块大小。
从逻辑上讲,启动grid_x * grid_y块并将其展平为一维网格:grid = (grid_size, 1, 1)。
第 2 步:在内核中获取块 ID
在内核内部,每个块通过ct.bid(0)获取其唯一的标识符:
| bid = ct.bid(0) # Return value range: [0, grid_size-1] |
ct.bid(0)在 x 轴维度中查询当前块的 ID。
参数 0 表示第一个维度 ( x 轴) ,对应网格定义中的第一个元素(grid_size, 1, 1).
每个块都有一个唯一的一维坐标: bid = 0, 1, 2, …, grid_size-1.
第 3 步:将 1D 块 ID 映射到 2D 图块坐标
现在的问题是块 ID (bid) 为一维,而输出矩阵是二维。需要明确该块应处理的行和列图块。swizzle_2d_from_bid()函数可用于确定该块所负责的行和列图块。
| bidx, bidy = swizzle_2d_from_bid(M, N, tm, tn, GROUP_SIZE_M, bid) |
输出结果:
bidx:当前块负责的输出图块在 M 维度上的行索引。取值范围:【0,grid_x -1】。
bidy:当前块负责的输出图块在 N 维度上的列索引。取值范围:【0,grid_y -1】。
特定的映射逻辑涉及 Swizzling(用于提升内存访问效率),我们将在第 4 节中详细解释这一点。目前,只需理解它将 1D 块 ID 转换为 2D 图块坐标即可。
5. 准备累加器:初始化输出图块
在循环执行 K 维度之前,您需要先创建一个累加器以存储中间结果:
| num_tiles_k = ct.num_tiles(A, axis=1, shape=(tm, tk)) accumulator = ct.full((tm, tn), 0, dtype=ct.float32) |
num_tiles_k: 计算在 K 维度中需要处理的图块数量。
accumulator: 用于累加结果的形状 (tm,tn) 零矩阵。
使用 float32 可确保数值精度并避免累积错误。
6. 核心计算循环:沿 K 维遍历
这是矩阵乘法的核心。接下来,循环遍历 K 维度中的每个图块,并累加结果:
| for k in range(num_tiles_k): # Load tiles a = ct.load(A, index=(bidx, k), shape=(tm, tk), padding_mode=zero_pad) b = ct.load(B, index=(k, bidy), shape=(tk, tn), padding_mode=zero_pad) # Accumulate accumulator = ct.mma(a, b, accumulator) |
加载数据:
ct.load(A, index=(bidx, k), shape=(tm, tk)): 从矩阵 A 中加载图块。
index=(bidx, k): 指定要在图块空间中加载的图块坐标。
shape=(tm, tk): 图块的大小。
padding_mode=zero_pad: 如果负载数据超出范围,则用 0 填充。
矩阵乘积累加:
ct.mma(a, b, accumulator): 乘a*b, 加到accumulator,然后把结果保存至accumulator(mma表示矩阵乘积累加)
当a和b的形状满足 Tensor Core 要求时,cuTile 会自动调用 GPU 的 Tensor Core 来加速此操作。
循环结束后,累加器将保存输出图块的完整结果。
写回结果:存储到全局内存
随后,将计算结果写回全局内存:
| accumulator = ct.astype(accumulator, C.dtype) ct.store(C, index=(bidx, bidy), tile=accumulator) |
首先,将 float32 累加器转换为输出矩阵的数据类型。
使用ct.store()将图块写回到全局内存中的对应位置。
启动核函数:主机侧代码
现在从主机启动内核。首先,查看全部代码。
| def cutile_matmul(A: torch.Tensor, B: torch.Tensor) -> torch.Tensor: # Determine tile sizes based on dtype if A.dtype.itemsize == 2: # float16/bfloat16 tm, tn, tk = 128, 256, 64 else: # float32 tm, tn, tk = 32, 32, 32 m, k = A.shape _, n = B.shape # Calculate grid dimensions grid_x = ceil(m / tm) grid_y = ceil(n / tn) grid_size = grid_x * grid_y grid = (grid_size, 1, 1) # Create output tensor C = torch.empty((m, n), device=A.device, dtype=A.dtype) # Launch kernel ct.launch(torch.cuda.current_stream(), grid, matmul_kernel, (A, B, C, tm, tn, tk)) return C |
在主机侧启动内核需要完成三个关键步骤:
第 1 步:计算网格大小
根据输入矩阵的维度和图块大小,计算所需块的数量:
| m, k = A.shape # Matrix A dimensions: m rows, k columns _, n = B.shape # Matrix B dimensions: k rows, n columns # Calculate number of Blocks needed grid_x = ceil(m / tm) # How many tiles needed for M dimension grid_y = ceil(n / tn) # How many tiles needed for N dimension grid_size = grid_x * grid_y # Total Blocks grid = (grid_size, 1, 1) # Defined as 1D grid |
ceil()向上取整,确保覆盖所有元素 (即使矩阵维度无法被图块大小整除) 。
将 2D 块布局扁平化为 1D 网格可简化启动逻辑。
第 2 步:设置图块大小 (编译时常量)
根据数据类型选择合适的图块大小:
| if A.dtype.itemsize == 2: # float16/bfloat16 (2 bytes per element) tm, tn, tk = 128, 256, 64 else: # float32 (4 bytes per element) tm, tn, tk = 32, 32, 32 |
这些参数作为编译期常量传递给内核:
tm: 输出图块行 ( M 维) 。
tn: 输出图块列 ( N 个维度) 。
tk: 每次以 K 维加载的图块大小。
注意:此处的图块大小配置仅为示例。在实践中,不同的 GPU 架构需要相应的参数配置以达到理想性能。合适的配置取决于 M/ N/ K 大小、GPU 架构、共享内存大小、寄存器数量、SM 数量等因素。在开发过程中,建议使用性能分析工具(如 NVIDIA Nsight Compute)确定较优参数。TileGym 提供了一个自动调整程序,可用于自动获取较优参数。
第 3 步:调用ct.launch()启动核函数
| C = torch.empty((m, n), device=A.device, dtype=A.dtype) # Create output tensor ct.launch( torch.cuda.current_stream(), # CUDA stream grid, # Grid dimensions: (grid_size, 1, 1) matmul_kernel, # Kernel function (A, B, C, tm, tn, tk) # Arguments passed to kernel ) |
Stream:指定核函数在哪个 CUDA 流上执行(用于实现异步执行与多流并发)。
网格:定义要启动的线程块数量。
内核函数:要执行的 GPU 内核(即使用 ct.kernel 装饰的函数)。
参数元组: 传递给内核的所有参数;其中tm、tn和tk将被编译器识别为常量。
性能优化:Swizzle
为了提升性能,我们引入了早期的 Swizzle。如swizzle_2d_from_bid的代码所示。
| def swizzle_2d_from_bid(M, N, tm, tn, GROUP_SIZE_M, bid): # Get the global IDs of a given CUDA block in a 1D grid. num_bid_m = ct.cp(M, tm) num_bid_n = ct.cp(N, tn) num_bid_in_group = GROUP_SIZE_M * num_bid_n group_id = bid // num_bid_in_group first_bid_m = group_id * GROUP_SIZE_M group_size_m = min(num_bid_m - first_bid_m, GROUP_SIZE_M) bid_m = first_bid_m + (bid % group_size_m) bid_n = (bid % num_bid_in_group) // group_size_m return bid_m, bid_n |
Swizzle 如何提高性能?
它通过分组与交错的方式,将块 ID 重新映射到平铺索引,以更高效地利用缓存。
本图以输出矩阵的四个元素(着色区域)为例,对比了线性内存访问与 Swizzled 内存访问方式。
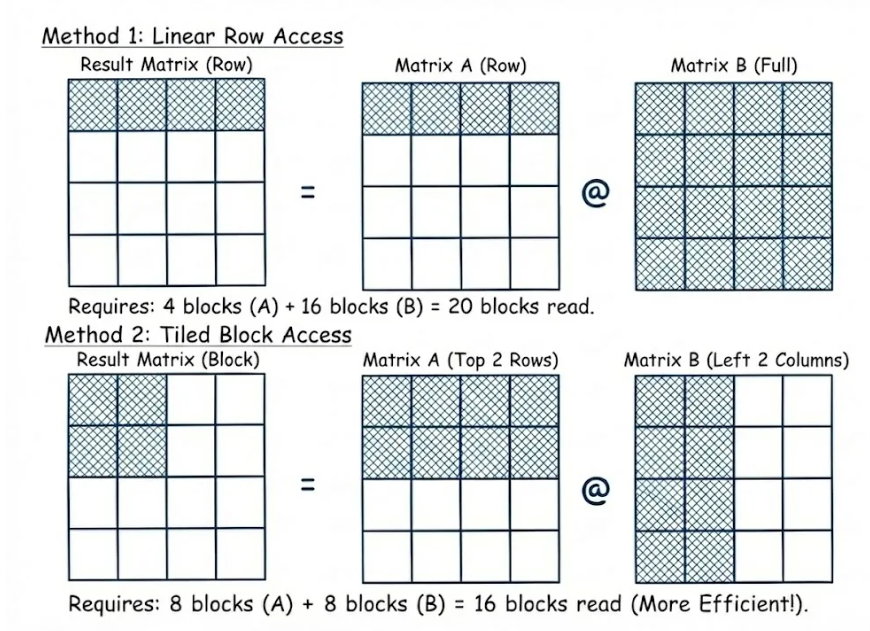
图 2。线性行访问与分块平铺访问的直观对比
方法 1:线性行访问
计算结果矩阵中的一行数据(例如四个元素)时,
需要读取左侧矩阵的四个块以及右侧矩阵的全部 16 个块。
总的内存访问量:20 个数据块。
由于正确的矩阵数据会被频繁加载并迅速替换,导致缓存命中率降低。
方法 2:Swizzle/ 平铺块访问
将计算重新组织为 2 × 2 的本地块。
仅需读取左侧矩阵中的 8 个相关块和右侧矩阵中的 8 个相关块。
总显存访问量: 16 个数据块 (减少 20%).
数据局部性更优,缓存命中率随之提高。
性能基准测试
为了验证已实现的矩阵乘法内核的性能,测试在NVIDIA GeForce RTX 5080(计算能力 12.0)上进行。完整的基准测试代码可在TileGym资源库中找到。 请按照安装说明完成配置后,参照快速入门指南运行本测试及其他相关测试。
测试配置:
数据类型: float16
矩阵形状: 标准方形矩阵(N × N)
测试规模: N = 1024、2048、4096、8192、16384(即 2¹⁰ 到 2¹⁴)
下图展示了不同矩阵规模下的性能表现。
图 3. NVIDIA GeForce RTX 5080 上 cuTile 与 PyTorch 的 TFLOP/s 性能随矩阵大小变化的对比
结果表明:
在大型矩阵规模下,cuTile 实现能够充分释放 GPU 的计算能力。
通过合理的图块大小配置与 swizzle 优化,cuTile 实现的性能较业界先进实现(PyTorch 调用 cuBLAS)提升90% 以上。
总结
这个经典的矩阵乘法示例展示了使用 cuTile 实现 GPU 内核的完整过程。尽管矩阵乘法较为简单,但它涵盖了 Tile 编程的核心理念。掌握这些概念后,您将能够运用 cuTile 实现多种高性能 GPU 内核。请在TileGym 库中查看完整的矩阵乘法示例及其他相关内容,立即开始编写高效的图块代码。
关于作者
Jinman Xie 是 NVIDIA 的深度学习性能架构师。她毕业于浙江大学计算机科学与技术学院。Jinman 的主要关注领域包括深度学习模型加速、内核优化和深度学习编译器技术。
Qiqi Xiao 毕业于北京大学计算机科学专业,并获得卡内基梅隆大学硕士学位。Qiqi 专注于 AI 推理框架、深度学习模型优化和编译器技术。